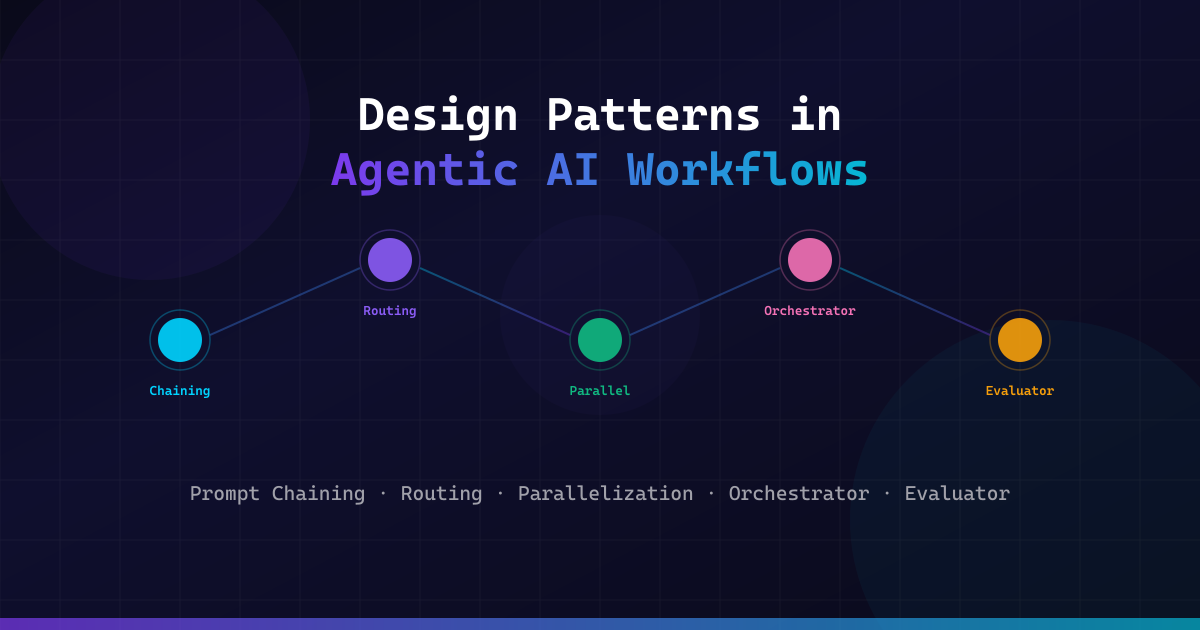
As AI agents evolve from simple prompt-response tools into autonomous systems capable of reasoning, planning, and executing multi-step tasks, the need for structured architectural patterns becomes critical. Just as traditional software engineering relies on design patterns like MVC, Observer, and Strategy to build maintainable systems, agentic AI workflows demand their own set of proven patterns to handle complexity, reliability, and scale.
This article explores the five foundational design patterns that power modern agentic AI workflows: Prompt Chaining, Routing, Parallelization, Orchestrator–Workers, and Evaluator–Optimizer. Each pattern addresses a distinct challenge in building production-grade AI systems — from sequential reasoning to dynamic task delegation, concurrent execution, centralized coordination, and iterative refinement. We provide detailed Python implementations using LangChain, CrewAI, and the Transformers ecosystem, complete with error handling, type annotations, and async patterns that reflect real-world engineering standards.
Whether you're building an autonomous coding assistant, a multi-agent research pipeline, or an AI-driven content platform, understanding these patterns will give you the architectural vocabulary to design systems that are robust, composable, and scalable.
Pattern 1: Prompt Chaining
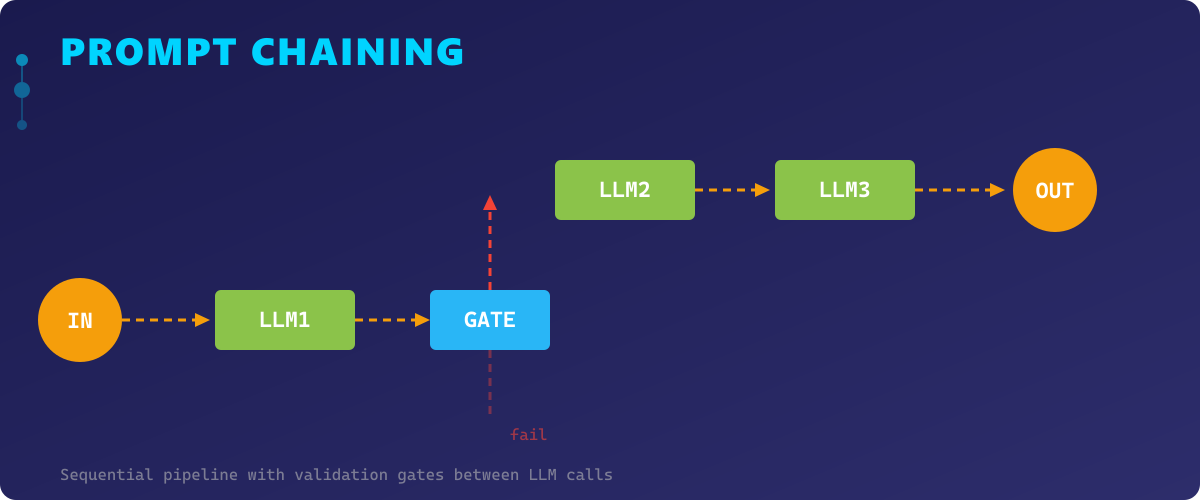
Prompt Chaining is the most intuitive pattern — it decomposes a complex task into a sequential pipeline where the output of one LLM call becomes the input of the next. Each step in the chain handles a focused subtask, making the overall system easier to debug, test, and iterate on.
This pattern excels when the task has a natural order of operations. For example, generating a blog post might involve: (1) research key points, (2) create an outline, (3) write the draft, (4) edit for tone and clarity. Each step builds on the previous one, and you can insert validation gates between steps to catch errors early.
The key advantage of Prompt Chaining over a single monolithic prompt is controllability. By breaking the task into discrete steps, you gain visibility into intermediate results, can retry individual steps on failure, and can swap out models for specific steps (e.g., a faster model for summarization, a more capable one for reasoning).
However, Prompt Chaining introduces latency proportional to the number of steps, since each must complete before the next begins. It also risks error propagation — a hallucination in step 2 will corrupt all downstream steps. Mitigation strategies include validation functions between steps, confidence scoring, and fallback logic.
import asyncio
from typing import Optional
from dataclasses import dataclass
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
@dataclass
class ChainStep:
"""Represents a single step in a prompt chain."""
name: str
prompt_template: str
model: Optional[str] = "gpt-4o"
temperature: float = 0.7
class PromptChain:
"""
Implements the Prompt Chaining pattern for sequential LLM processing.
Each step's output feeds into the next step's input.
"""
def __init__(self, steps: list[ChainStep], api_key: str):
self.steps = steps
self.api_key = api_key
self.parser = StrOutputParser()
self.intermediate_results: dict[str, str] = {}
def _build_chain(self, step: ChainStep):
"""Build a LangChain runnable for a single step."""
llm = ChatOpenAI(
model=step.model,
temperature=step.temperature,
api_key=self.api_key,
)
prompt = ChatPromptTemplate.from_template(step.prompt_template)
return prompt | llm | self.parser
async def execute(self, initial_input: str) -> str:
"""
Execute the full chain sequentially, passing each output to the next step.
Args:
initial_input: The initial input to feed into the first step.
Returns:
The final output after all steps have been executed.
"""
current_input = initial_input
for step in self.steps:
chain = self._build_chain(step)
try:
result = await chain.ainvoke({"input": current_input})
self.intermediate_results[step.name] = result
current_input = result
print(f"[✓] Step '{step.name}' completed ({len(result)} chars)")
except Exception as e:
print(f"[✗] Step '{step.name}' failed: {e}")
raise
return current_input
async def main():
"""Demonstrate Prompt Chaining for a content generation pipeline."""
steps = [
ChainStep(
name="research",
prompt_template="Extract 5 key technical points about: {input}",
),
ChainStep(
name="outline",
prompt_template="Create a structured outline from these points:\n{input}",
),
ChainStep(
name="draft",
prompt_template="Write a professional article draft from this outline:\n{input}",
temperature=0.8,
),
ChainStep(
name="polish",
prompt_template="Edit this draft for clarity, tone, and technical accuracy:\n{input}",
temperature=0.3,
),
]
chain = PromptChain(steps=steps, api_key="your_openai_api_key")
result = await chain.execute("Retrieval-Augmented Generation in production systems")
print(f"\nFinal output:\n{result[:500]}...")
if __name__ == "__main__":
asyncio.run(main())This implementation demonstrates a reusable Prompt Chaining pipeline with named steps, intermediate result tracking, and error handling. Each step is independently configurable with its own model and temperature.
Pattern 2: Routing
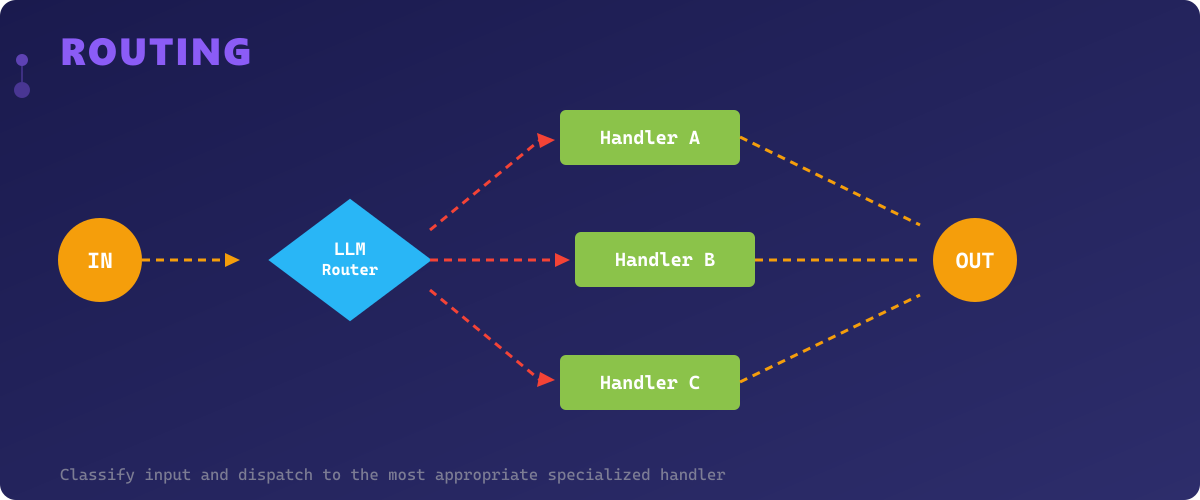
Routing is a classification-first pattern where an initial LLM call (or a lightweight classifier) examines the input and dispatches it to the most appropriate handler. Instead of forcing a single prompt to handle every possible input type, Routing creates specialized paths — each optimized for a specific category of request.
Think of it as a smart switch statement powered by AI. A customer support system might route messages to a billing agent, a technical support agent, or an escalation handler based on the detected intent. A code assistant might route to different handlers for Python, JavaScript, or SQL queries.
The Routing pattern is powerful because it enables specialization without complexity. Each handler can use a different prompt, model, temperature, or even a different tool set. This is more cost-effective than using the most expensive model for every request, and it produces better results because each handler is tuned for its specific domain.
The main challenge is ensuring the router's classification accuracy. A misrouted request leads to a poor response from an inappropriate handler. Strategies to improve routing include few-shot examples in the router prompt, confidence thresholds with fallback routes, and multi-label routing for ambiguous inputs.
import asyncio
from enum import Enum
from typing import Callable, Awaitable
from dataclasses import dataclass, field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
class RouteCategory(str, Enum):
"""Supported route categories for the AI assistant."""
CODE_REVIEW = "code_review"
BUG_FIX = "bug_fix"
ARCHITECTURE = "architecture"
GENERAL = "general"
@dataclass
class Route:
"""Defines a route with its handler configuration."""
category: RouteCategory
description: str
prompt_template: str
model: str = "gpt-4o"
temperature: float = 0.7
class AgenticRouter:
"""
Implements the Routing pattern — classifies input and dispatches
to specialized handlers for optimal response quality.
"""
def __init__(self, routes: list[Route], api_key: str):
self.routes = {r.category: r for r in routes}
self.api_key = api_key
self.parser = StrOutputParser()
async def classify(self, user_input: str) -> RouteCategory:
"""
Classify the user input into one of the supported categories.
Args:
user_input: The raw user request.
Returns:
The detected RouteCategory.
"""
route_descriptions = "\n".join(
f"- {r.category.value}: {r.description}" for r in self.routes.values()
)
classifier_prompt = ChatPromptTemplate.from_template(
"Classify the following request into exactly one category.\n\n"
"Categories:\n{routes}\n\n"
"Request: {input}\n\n"
"Respond with ONLY the category name, nothing else."
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0, api_key=self.api_key)
chain = classifier_prompt | llm | self.parser
result = await chain.ainvoke({"routes": route_descriptions, "input": user_input})
category_str = result.strip().lower()
try:
return RouteCategory(category_str)
except ValueError:
print(f"[!] Unknown category '{category_str}', falling back to GENERAL")
return RouteCategory.GENERAL
async def handle(self, user_input: str) -> str:
"""
Route the input to the appropriate handler and return the response.
Args:
user_input: The raw user request.
Returns:
The response from the specialized handler.
"""
category = await self.classify(user_input)
route = self.routes[category]
print(f"[→] Routed to: {category.value}")
llm = ChatOpenAI(
model=route.model,
temperature=route.temperature,
api_key=self.api_key,
)
prompt = ChatPromptTemplate.from_template(route.prompt_template)
chain = prompt | llm | self.parser
return await chain.ainvoke({"input": user_input})
async def main():
"""Demonstrate the Routing pattern for a development assistant."""
routes = [
Route(
category=RouteCategory.CODE_REVIEW,
description="Requests to review, critique, or improve existing code",
prompt_template="You are a senior code reviewer. Provide detailed feedback:\n{input}",
temperature=0.3,
),
Route(
category=RouteCategory.BUG_FIX,
description="Requests to find and fix bugs in code",
prompt_template="You are a debugging expert. Identify the bug and provide a fix:\n{input}",
temperature=0.2,
),
Route(
category=RouteCategory.ARCHITECTURE,
description="Questions about system design, architecture, or patterns",
prompt_template="You are a software architect. Provide a detailed design analysis:\n{input}",
model="gpt-4o",
temperature=0.7,
),
Route(
category=RouteCategory.GENERAL,
description="General programming questions and explanations",
prompt_template="You are a helpful programming assistant. Answer clearly:\n{input}",
model="gpt-4o-mini",
),
]
router = AgenticRouter(routes=routes, api_key="your_openai_api_key")
response = await router.handle("My FastAPI endpoint returns 500 when the database connection pool is exhausted")
print(f"\nResponse:\n{response}")
if __name__ == "__main__":
asyncio.run(main())This Routing implementation uses an enum-based category system with fallback handling. The lightweight classifier uses a cheaper model (gpt-4o-mini) while specialized handlers can use more powerful models as needed.
Pattern 3: Parallelization
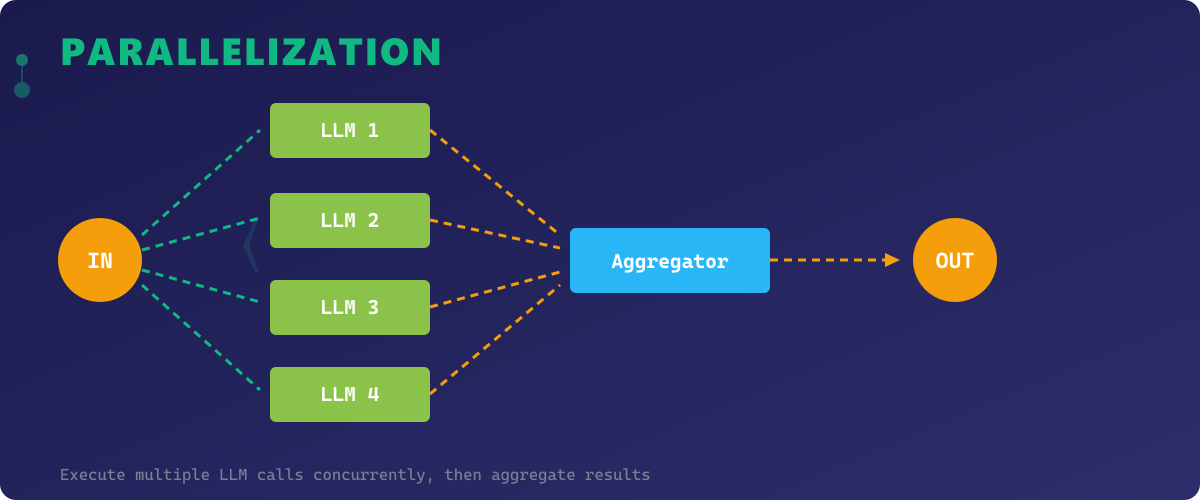
Parallelization tackles the latency bottleneck inherent in sequential processing by executing multiple LLM calls concurrently. This pattern comes in two flavors: sectioning (splitting a task into independent subtasks run in parallel) and voting (running the same task multiple times and aggregating results for higher reliability).
The sectioning approach is ideal when different aspects of a problem are independent. For example, analyzing a codebase might involve checking security vulnerabilities, code style, performance issues, and documentation coverage — all of which can run simultaneously. The voting approach is valuable for high-stakes decisions where you want consensus from multiple independent evaluations.
Parallelization dramatically reduces total latency — if you have 4 independent subtasks each taking 3 seconds, sequential execution takes 12 seconds while parallel execution takes only ~3 seconds. Combined with async patterns in Python, this makes the pattern highly efficient.
The trade-offs include increased API costs (more concurrent calls), complexity in result aggregation, and the need for careful error handling when some parallel tasks fail while others succeed. Implementing proper timeout management and partial-failure strategies is essential for production systems.
import asyncio
from typing import Any
from dataclasses import dataclass
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
@dataclass
class ParallelTask:
"""Defines a single task to be executed in parallel."""
name: str
prompt_template: str
model: str = "gpt-4o"
temperature: float = 0.7
class ParallelExecutor:
"""
Implements the Parallelization pattern — runs multiple LLM tasks
concurrently and aggregates results.
"""
def __init__(self, api_key: str, timeout: float = 30.0):
self.api_key = api_key
self.timeout = timeout
self.parser = StrOutputParser()
async def _execute_task(self, task: ParallelTask, input_data: str) -> dict[str, Any]:
"""Execute a single parallel task with error handling."""
llm = ChatOpenAI(
model=task.model,
temperature=task.temperature,
api_key=self.api_key,
)
prompt = ChatPromptTemplate.from_template(task.prompt_template)
chain = prompt | llm | self.parser
try:
result = await asyncio.wait_for(
chain.ainvoke({"input": input_data}),
timeout=self.timeout,
)
return {"task": task.name, "status": "success", "result": result}
except asyncio.TimeoutError:
return {"task": task.name, "status": "timeout", "result": None}
except Exception as e:
return {"task": task.name, "status": "error", "result": str(e)}
async def run_sectioned(
self, tasks: list[ParallelTask], input_data: str
) -> list[dict[str, Any]]:
"""
Run independent subtasks in parallel (sectioning strategy).
Args:
tasks: List of independent tasks to execute concurrently.
input_data: Shared input data for all tasks.
Returns:
List of results from all parallel tasks.
"""
coroutines = [self._execute_task(task, input_data) for task in tasks]
results = await asyncio.gather(*coroutines, return_exceptions=False)
succeeded = sum(1 for r in results if r["status"] == "success")
print(f"[✓] {succeeded}/{len(tasks)} tasks completed successfully")
return results
async def run_voting(
self, task: ParallelTask, input_data: str, num_votes: int = 3
) -> dict[str, Any]:
"""
Run the same task multiple times and aggregate results (voting strategy).
Args:
task: The task to execute multiple times.
input_data: Input data for the task.
num_votes: Number of parallel executions.
Returns:
Aggregated voting results.
"""
tasks = [
ParallelTask(
name=f"{task.name}_vote_{i}",
prompt_template=task.prompt_template,
model=task.model,
temperature=task.temperature,
)
for i in range(num_votes)
]
results = await self.run_sectioned(tasks, input_data)
successful_results = [r["result"] for r in results if r["status"] == "success"]
return {
"votes": successful_results,
"total_votes": len(successful_results),
"consensus": self._find_consensus(successful_results),
}
@staticmethod
def _find_consensus(results: list[str]) -> str:
"""Simple consensus: return the most common result or first if all unique."""
if not results:
return ""
from collections import Counter
counter = Counter(results)
return counter.most_common(1)[0][0]
async def main():
"""Demonstrate both sectioning and voting parallelization strategies."""
executor = ParallelExecutor(api_key="your_openai_api_key", timeout=30.0)
# Sectioning: analyze code from multiple angles simultaneously
code_input = "async def fetch_users(db): return await db.query('SELECT * FROM users')"
analysis_tasks = [
ParallelTask(
name="security_audit",
prompt_template="Analyze this code for security vulnerabilities:\n{input}",
temperature=0.2,
),
ParallelTask(
name="performance_review",
prompt_template="Analyze this code for performance issues:\n{input}",
temperature=0.3,
),
ParallelTask(
name="best_practices",
prompt_template="Review this code against Python best practices:\n{input}",
temperature=0.3,
),
ParallelTask(
name="documentation",
prompt_template="Suggest docstrings and type hints for this code:\n{input}",
temperature=0.5,
),
]
print("=== Sectioning Strategy ===")
results = await executor.run_sectioned(analysis_tasks, code_input)
for r in results:
print(f"\n[{r['task']}] ({r['status']}):\n{r['result'][:200] if r['result'] else 'N/A'}...")
# Voting: get consensus on a classification task
print("\n=== Voting Strategy ===")
classification_task = ParallelTask(
name="severity_classification",
prompt_template="Classify the severity of this code issue (LOW/MEDIUM/HIGH/CRITICAL):\n{input}\nRespond with only the severity level.",
temperature=0.5,
)
voting_result = await executor.run_voting(classification_task, code_input, num_votes=5)
print(f"Votes: {voting_result['votes']}")
print(f"Consensus: {voting_result['consensus']}")
if __name__ == "__main__":
asyncio.run(main())This implementation showcases both parallelization strategies — sectioning for independent subtasks and voting for consensus. It includes timeout management, partial failure handling, and a simple consensus algorithm.
Pattern 4: Orchestrator–Workers
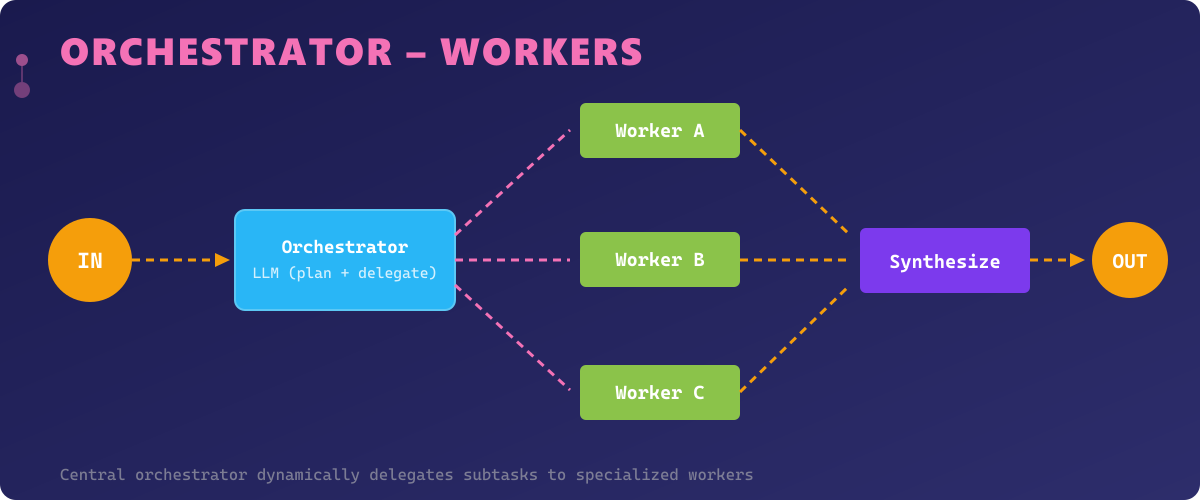
The Orchestrator–Workers pattern introduces a central coordinator (the orchestrator) that dynamically breaks down complex tasks and delegates subtasks to specialized worker agents. Unlike Prompt Chaining where the flow is predetermined, the orchestrator decides at runtime which workers to invoke, in what order, and how to synthesize their outputs.
This pattern mirrors the structure of a tech lead managing a development team. The orchestrator analyzes the incoming task, creates a work plan, assigns subtasks to the most appropriate workers, monitors progress, and assembles the final deliverable. Each worker is a specialized agent with its own tools, prompts, and capabilities.
The Orchestrator–Workers pattern is the most flexible of all five patterns. It can dynamically adapt to unforeseen task requirements, parallelize independent subtasks, and handle complex dependencies between workers. It's ideal for open-ended tasks like "build a REST API for user management" or "research and write a technical report on quantum computing."
The downside is increased complexity and cost. The orchestrator itself requires a capable model (GPT-4 class) to make good delegation decisions, and the overall token usage can be significant. Proper logging and observability are essential to debug multi-agent interactions.
import asyncio
from typing import Any
from dataclasses import dataclass, field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
@dataclass
class WorkerAgent:
"""A specialized worker agent with a defined capability."""
name: str
specialty: str
prompt_template: str
model: str = "gpt-4o"
temperature: float = 0.7
@dataclass
class TaskPlan:
"""A plan created by the orchestrator."""
subtasks: list[dict[str, str]] = field(default_factory=list)
execution_order: list[str] = field(default_factory=list)
class Orchestrator:
"""
Implements the Orchestrator-Workers pattern.
A central orchestrator decomposes tasks and delegates to specialized workers.
"""
def __init__(self, workers: list[WorkerAgent], api_key: str):
self.workers = {w.name: w for w in workers}
self.api_key = api_key
self.parser = StrOutputParser()
self.results: dict[str, str] = {}
async def plan(self, task: str) -> TaskPlan:
"""
Analyze the task and create an execution plan.
Args:
task: The complex task to decompose.
Returns:
A TaskPlan with subtasks and execution order.
"""
worker_list = "\n".join(
f"- {w.name}: {w.specialty}" for w in self.workers.values()
)
planning_prompt = ChatPromptTemplate.from_template(
"You are an orchestrator that decomposes complex tasks.\n\n"
"Available workers:\n{workers}\n\n"
"Task: {task}\n\n"
"Create a plan by listing subtasks in order. For each subtask, specify:\n"
"- worker: the worker name to handle it\n"
"- description: what the worker should do\n\n"
"Format each subtask as: WORKER_NAME | DESCRIPTION\n"
"One subtask per line. Only use available worker names."
)
llm = ChatOpenAI(model="gpt-4o", temperature=0.3, api_key=self.api_key)
chain = planning_prompt | llm | self.parser
raw_plan = await chain.ainvoke({"workers": worker_list, "task": task})
plan = TaskPlan()
for line in raw_plan.strip().split("\n"):
if "|" in line:
parts = line.split("|", 1)
worker_name = parts[0].strip()
description = parts[1].strip()
if worker_name in self.workers:
plan.subtasks.append({"worker": worker_name, "description": description})
plan.execution_order.append(worker_name)
print(f"[📋] Plan created with {len(plan.subtasks)} subtasks")
return plan
async def delegate(self, worker_name: str, subtask: str, context: str = "") -> str:
"""
Delegate a subtask to a specific worker.
Args:
worker_name: Name of the worker to delegate to.
subtask: Description of the subtask.
context: Previous results for context.
Returns:
The worker's output.
"""
worker = self.workers[worker_name]
llm = ChatOpenAI(
model=worker.model,
temperature=worker.temperature,
api_key=self.api_key,
)
prompt = ChatPromptTemplate.from_template(worker.prompt_template)
chain = prompt | llm | self.parser
result = await chain.ainvoke({"input": subtask, "context": context})
self.results[worker_name] = result
print(f"[⚙] Worker '{worker_name}' completed subtask")
return result
async def synthesize(self, task: str) -> str:
"""Synthesize all worker outputs into a final deliverable."""
all_results = "\n\n".join(
f"### {name}:\n{result}" for name, result in self.results.items()
)
synthesis_prompt = ChatPromptTemplate.from_template(
"You are an orchestrator assembling the final output.\n\n"
"Original task: {task}\n\n"
"Worker outputs:\n{results}\n\n"
"Synthesize these into a cohesive, professional final deliverable."
)
llm = ChatOpenAI(model="gpt-4o", temperature=0.5, api_key=self.api_key)
chain = synthesis_prompt | llm | self.parser
return await chain.ainvoke({"task": task, "results": all_results})
async def execute(self, task: str) -> str:
"""
Full orchestration: plan, delegate, and synthesize.
Args:
task: The complex task to execute.
Returns:
The final synthesized output.
"""
plan = await self.plan(task)
context = ""
for subtask in plan.subtasks:
result = await self.delegate(
worker_name=subtask["worker"],
subtask=subtask["description"],
context=context,
)
context += f"\n{subtask['worker']}: {result[:500]}"
return await self.synthesize(task)
async def main():
"""Demonstrate the Orchestrator-Workers pattern for API development."""
workers = [
WorkerAgent(
name="architect",
specialty="System design, API structure, database schema",
prompt_template="You are a software architect.\nContext: {context}\nTask: {input}",
temperature=0.5,
),
WorkerAgent(
name="developer",
specialty="Python implementation, FastAPI, SQLAlchemy code",
prompt_template="You are a senior Python developer.\nContext: {context}\nTask: {input}",
temperature=0.4,
),
WorkerAgent(
name="security_expert",
specialty="Security review, authentication, authorization",
prompt_template="You are a security engineer.\nContext: {context}\nTask: {input}",
temperature=0.2,
),
WorkerAgent(
name="technical_writer",
specialty="API documentation, README files, usage examples",
prompt_template="You are a technical writer.\nContext: {context}\nTask: {input}",
temperature=0.6,
),
]
orchestrator = Orchestrator(workers=workers, api_key="your_openai_api_key")
result = await orchestrator.execute(
"Design and implement a REST API for a task management system with "
"user authentication, CRUD operations, and role-based access control"
)
print(f"\nFinal deliverable:\n{result[:1000]}...")
if __name__ == "__main__":
asyncio.run(main())This Orchestrator-Workers implementation features dynamic planning, sequential delegation with context passing, and a synthesis phase. The orchestrator creates execution plans at runtime based on available worker capabilities.
Pattern 5: Evaluator–Optimizer
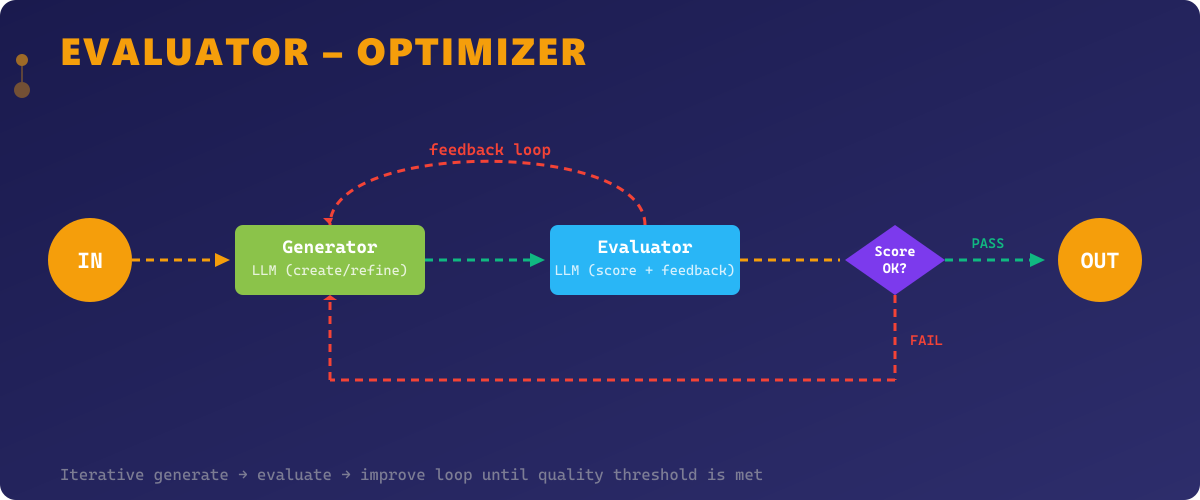
The Evaluator–Optimizer pattern creates an iterative refinement loop where one LLM generates output and another evaluates it against quality criteria. If the output doesn't meet the threshold, the evaluator provides specific feedback that the generator uses to improve. This cycle continues until the output meets quality standards or a maximum iteration count is reached.
This pattern is inspired by the generator-discriminator dynamic in GANs and by human review processes. A code generator produces code, a code reviewer identifies issues, and the generator rewrites based on the feedback. Each iteration narrows the gap between the current output and the desired quality.
The Evaluator–Optimizer pattern is essential for tasks where first-pass quality is insufficient — complex code generation, creative writing, data analysis, and any domain where iterative improvement yields significantly better results. It's also valuable for enforcing non-trivial quality criteria that are difficult to capture in a single prompt, such as "the code must be thread-safe" or "the explanation must be understandable by a junior developer."
The main considerations are cost and latency — each iteration doubles the API calls — and the risk of optimization loops where the evaluator and generator oscillate without converging. Setting clear evaluation criteria, a maximum iteration limit, and improvement-tracking logic are essential safeguards.
import asyncio
from typing import Optional
from dataclasses import dataclass, field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
@dataclass
class EvaluationResult:
"""Result of an evaluation cycle."""
score: float
passed: bool
feedback: str
iteration: int
@dataclass
class OptimizationHistory:
"""Tracks the optimization process across iterations."""
iterations: list[dict] = field(default_factory=list)
final_score: float = 0.0
converged: bool = False
class EvaluatorOptimizer:
"""
Implements the Evaluator-Optimizer pattern.
Iteratively refines output through a generate-evaluate-improve loop.
"""
def __init__(
self,
api_key: str,
generator_model: str = "gpt-4o",
evaluator_model: str = "gpt-4o",
max_iterations: int = 5,
quality_threshold: float = 8.0,
):
self.api_key = api_key
self.generator_model = generator_model
self.evaluator_model = evaluator_model
self.max_iterations = max_iterations
self.quality_threshold = quality_threshold
self.parser = StrOutputParser()
self.history = OptimizationHistory()
async def generate(self, task: str, feedback: Optional[str] = None) -> str:
"""
Generate or refine output based on the task and optional feedback.
Args:
task: The original task description.
feedback: Evaluator feedback from the previous iteration.
Returns:
The generated or refined output.
"""
if feedback:
template = (
"Original task: {task}\n\n"
"Your previous attempt received this feedback:\n{feedback}\n\n"
"Please improve your output based on the feedback. "
"Address each point specifically."
)
else:
template = (
"Complete the following task with high quality:\n{task}\n\n"
"Provide a thorough, well-structured, and professional response."
)
llm = ChatOpenAI(
model=self.generator_model, temperature=0.7, api_key=self.api_key
)
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | llm | self.parser
return await chain.ainvoke({"task": task, "feedback": feedback or ""})
async def evaluate(self, task: str, output: str, iteration: int) -> EvaluationResult:
"""
Evaluate the generated output against quality criteria.
Args:
task: The original task description.
output: The generated output to evaluate.
iteration: Current iteration number.
Returns:
An EvaluationResult with score, pass/fail, and feedback.
"""
eval_prompt = ChatPromptTemplate.from_template(
"You are a strict quality evaluator. Assess this output.\n\n"
"Original task: {task}\n\n"
"Output to evaluate:\n{output}\n\n"
"Evaluate on these criteria:\n"
"1. Correctness and accuracy\n"
"2. Completeness\n"
"3. Code quality (if applicable)\n"
"4. Clarity and readability\n"
"5. Best practices adherence\n\n"
"Respond in this exact format:\n"
"SCORE: [1-10]\n"
"FEEDBACK: [specific actionable improvements needed]"
)
llm = ChatOpenAI(
model=self.evaluator_model, temperature=0.2, api_key=self.api_key
)
chain = eval_prompt | llm | self.parser
raw_eval = await chain.ainvoke({"task": task, "output": output})
score = self._parse_score(raw_eval)
feedback = self._parse_feedback(raw_eval)
return EvaluationResult(
score=score,
passed=score >= self.quality_threshold,
feedback=feedback,
iteration=iteration,
)
async def optimize(self, task: str) -> tuple[str, OptimizationHistory]:
"""
Run the full optimization loop until quality threshold is met or max iterations reached.
Args:
task: The task to optimize.
Returns:
Tuple of (best output, optimization history).
"""
feedback = None
best_output = ""
best_score = 0.0
for i in range(1, self.max_iterations + 1):
print(f"\n[🔄] Iteration {i}/{self.max_iterations}")
# Generate
output = await self.generate(task, feedback)
print(f"[📝] Generated output ({len(output)} chars)")
# Evaluate
evaluation = await self.evaluate(task, output, i)
print(f"[📊] Score: {evaluation.score}/10 ({'PASS' if evaluation.passed else 'FAIL'})")
# Track best result
if evaluation.score > best_score:
best_score = evaluation.score
best_output = output
self.history.iterations.append({
"iteration": i,
"score": evaluation.score,
"passed": evaluation.passed,
"output_length": len(output),
})
if evaluation.passed:
print(f"[✓] Quality threshold met at iteration {i}")
self.history.converged = True
self.history.final_score = evaluation.score
return output, self.history
feedback = evaluation.feedback
print(f"[💡] Feedback: {feedback[:200]}...")
print(f"[!] Max iterations reached. Best score: {best_score}/10")
self.history.final_score = best_score
return best_output, self.history
@staticmethod
def _parse_score(raw: str) -> float:
"""Extract numeric score from evaluator output."""
for line in raw.split("\n"):
if line.strip().upper().startswith("SCORE:"):
try:
return float(line.split(":", 1)[1].strip().split("/")[0].strip())
except (ValueError, IndexError):
pass
return 5.0
@staticmethod
def _parse_feedback(raw: str) -> str:
"""Extract feedback text from evaluator output."""
for i, line in enumerate(raw.split("\n")):
if line.strip().upper().startswith("FEEDBACK:"):
return "\n".join(raw.split("\n")[i:]).replace("FEEDBACK:", "", 1).strip()
return raw
async def main():
"""Demonstrate the Evaluator-Optimizer pattern for code generation."""
optimizer = EvaluatorOptimizer(
api_key="your_openai_api_key",
max_iterations=4,
quality_threshold=8.0,
)
task = (
"Write a Python async context manager for database connection pooling. "
"It should support configurable pool size, connection timeout, health checks, "
"and graceful shutdown. Include type hints and comprehensive docstrings."
)
best_output, history = await optimizer.optimize(task)
print(f"\n{'='*60}")
print(f"Optimization complete in {len(history.iterations)} iterations")
print(f"Final score: {history.final_score}/10")
print(f"Converged: {history.converged}")
print(f"Score progression: {[it['score'] for it in history.iterations]}")
print(f"\nBest output:\n{best_output[:1000]}...")
if __name__ == "__main__":
asyncio.run(main())This Evaluator-Optimizer implementation features a structured evaluation criteria system, score parsing, best-output tracking across iterations, and a complete optimization history for observability.
Combining Patterns for Production Systems
In practice, production AI systems rarely use a single pattern in isolation. The real power emerges when you compose patterns together. A customer support platform might use Routing to classify incoming tickets, Parallelization to gather relevant context from multiple data sources simultaneously, Orchestrator–Workers to coordinate specialist agents for complex issues, and Evaluator–Optimizer to ensure response quality before sending to the customer.
When combining patterns, consider these architectural principles:
- Start simple — begin with Prompt Chaining, the easiest pattern to implement and debug. Only introduce more complex patterns when you have evidence that simplicity is insufficient.
- Measure everything — track latency, cost, quality scores, and failure rates per pattern. This data will guide optimization decisions.
- Design for failure — every pattern needs graceful degradation. What happens when a worker fails? When the evaluator disagrees with itself? When the router misclassifies?
- Keep humans in the loop — use the Evaluator–Optimizer pattern to flag outputs for human review when confidence is low, rather than silently serving poor results.
The design patterns presented in this article provide a robust vocabulary for reasoning about agentic AI system architecture. As the field matures, we can expect these patterns to evolve and new ones to emerge — but the fundamentals of decomposition, specialization, parallelism, coordination, and iterative refinement will remain the bedrock of effective AI agent design.
📂 Source Code
All code examples from this article are available on GitHub: OneManCrew/design-patterns-agentic-ai