This is Part 2 in a series on retrieval-powered AI systems. Part 1 walked from Classic RAG to Agentic RAG to a Multi-Agent Search system with semantic, SQL, and web tools. That architecture works beautifully — for the first five turns. After that, something predictable happens: the agent starts forgetting its plan, repeating searches, and producing answers that drift from the question.
The problem isn't the model. The problem is that we asked one model to do four different cognitive jobs at the same time inside a single context window: plan, retrieve, evaluate, and remember. Humans don't do this either. We split fast, automatic thinking from slow, deliberate thinking — and the science behind that split has a name.
This article builds Cog-RAG — short for Cognitive RAG — an architectural pattern that takes Daniel Kahneman's dual-process theory and turns it into a production retrieval agent. By the end of this article you will have:
- A clear diagnosis of why ReAct loops degrade past ~5 retrieval hops.
- A full LangGraph implementation of a Planner / Worker / Working Memory system.
- A working pattern for cognitive compression — turning 4 KB of raw tool output into a 240-character insight.
- A benchmark table comparing Cog-RAG to Agentic RAG on token cost, multi-hop accuracy, and stuck-loop rate.
- An honest take on when not to use Cog-RAG — because every architectural choice has a tax.
All code in this article is runnable and lives on GitHub: OneManCrew/cog-rag-langgraph
Part 1: The Cognitive Overload Problem
Re-read the Multi-Agent Search Agent from Part 1. The Search Agent receives a request, picks one of three tools, gets back raw output (often 2-8 KB), and the LLM does all of the following in one shot:
- decides whether the result is relevant
- decides whether to call another tool
- decides which query to use next
- maintains a mental model of what the user originally asked
- synthesizes everything into the next response
This is the ReAct loop introduced by Yao et al. (2022) — interleaved Reasoning and Acting in a single context window. It is elegant. It is also the source of every mid-run failure you've ever seen in an agentic system.
Run the agent on a multi-step question and watch the context window over time:
turn 1: [system] [user] [tool_schemas] ~3.5 KB
turn 2: [...] [tool_call: semantic_search]
[tool_result: 4.1 KB of raw chunks] ~7.6 KB
turn 3: [...] [tool_call: sql]
[tool_result: 2.4 KB of rows] ~10.0 KB
turn 4: [...] [tool_call: web]
[tool_result: 3.7 KB of snippets] ~13.7 KB
turn 5: [...] [tool_call: semantic_search again]
[tool_result: 4.0 KB of chunks] ~17.7 KB
turn 6: [final answer] ~18 KBEighteen kilobytes of mostly-noise dragged through every reasoning step. The problem is not that the model can't fit this — modern context windows are huge. The problem is that the planning quality of an LLM degrades sharply when the prompt fills with irrelevant material. The "lost in the middle" effect (Liu et al., 2023) is real, measurable, and devastating once you cross 5-7 hops.
You can see it in production with a single metric: plan adherence rate. Log the agent's first declared plan ("I need to check the database, then verify on the web, then synthesize"), then check whether the final answer actually executed those three steps. In a typical Agentic RAG system, plan adherence drops from ~95% at 2 hops to ~45% at 7 hops. The agent forgets what it set out to do.
The diagnosis: ReAct asks the model to plan and remember while drowning in raw retrieval output. Past a few hops, planning fails because the prompt is no longer mostly about the goal — it's mostly about chunks.
Part 2: Dual-Process Theory, in 60 Seconds
Daniel Kahneman's Thinking, Fast and Slow describes human cognition as the interaction of two systems:
- System 1 — fast, automatic, intuitive, parallel, low-effort. Reading a face, catching a ball, completing the phrase "bread and ___".
- System 2 — slow, deliberate, effortful, serial, capacity-limited. Multiplying 17 × 24, planning a route, deciding whether an argument is valid.
The crucial property of System 2 is that it has a strict working memory budget. You cannot consciously hold more than a handful of items in mind. The brain's solution is brutal: System 1 does the heavy lifting in the background, hands System 2 a summary, and System 2 does the deliberation on the summary alone. Raw sensory input never reaches the deliberative layer.
The mapping to LLM agents is direct, and once you see it you cannot unsee it:
| Cognitive system | Property | LLM-agent equivalent |
|---|---|---|
| System 1 | fast, parallel, low-effort | tool-using worker that fetches, summarizes, returns |
| System 2 | slow, serial, capacity-limited | planner that reasons over a small, curated workspace |
| Working memory | bounded buffer of meanings, not raw inputs | distilled insights, never raw chunks |
ReAct collapses these layers into one. Cog-RAG keeps them separate.
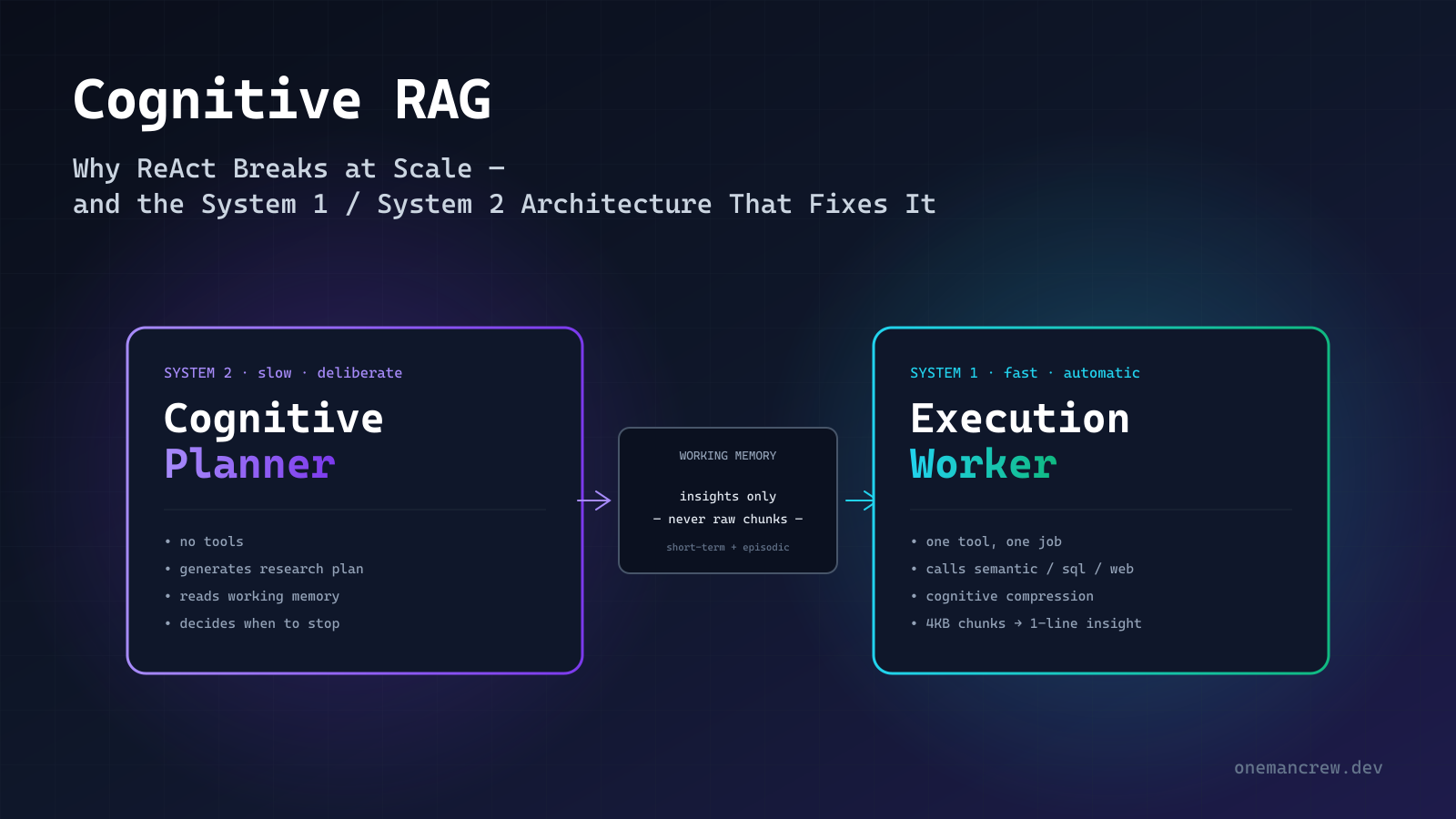
Part 3: The Cog-RAG Architecture
The architecture has three named components and one sacred rule.
┌────────────────┐
user ───►│ Cognitive │◄──── revisits every turn
│ Planner │ (System 2 — slow)
│ (no tools) │
└────────┬───────┘
│ insights only
▼
┌────────────────┐
│ Working Memory │ short-term + episodic
│ (insights) │ ┌─────────────────────┐
└────────┬───────┘ │ THE SACRED RULE: │
│ │ raw chunks NEVER │
▼ │ enter the planner. │
┌────────────────┐ └─────────────────────┘
│ Execution │ one step at a time
│ Worker │ (System 1 — fast)
│ semantic/SQL/ │ cognitive compression:
│ web → insight │ raw output → 1 insight
└────────────────┘The control flow is intentionally boring:
- Planner runs → produces a numbered research plan, or revises it, or finishes.
- Executor runs → takes the next step from the plan, picks one tool, fires it.
- Compression → raw output is distilled into a single Insight (1-2 sentences).
- Append → Insight goes into Working Memory, Worker hands control back.
- Planner runs again → reads the updated working memory, decides next move.
Note what happens on every loop: the planner sees a small, growing list of one-line insights. It never sees raw chunks. It never sees JSON blobs. Its prompt grows by ~80 tokens per turn instead of ~2,000.
That's the entire trick.
Part 4: The Cognitive State
Everything in Cog-RAG is enforced by the state object. The whole architecture is a discipline expressed as a TypedDict.
"""
The Cognitive State — the heart of Cog-RAG.
It enforces a strict discipline:
- The Planner only reads `working_memory` (a list of distilled insights).
- The Executor is the only component that touches raw tool output.
- Episodic memory is the long-form archive used for final synthesis.
"""
from __future__ import annotations
from dataclasses import dataclass
from typing import Optional, TypedDict
@dataclass
class Insight:
"""A compressed, planner-ready piece of information.
NOT a raw chunk. NOT a JSON blob from a tool. A single sentence (or two)
that answers a specific sub-question, with provenance.
"""
step: str # the sub-task this insight resolves
source_tool: str # 'semantic' | 'sql' | 'web'
text: str # the distilled insight (target: < 240 chars)
citation: str = "" # optional: source URL / table / doc id
def render(self) -> str:
cite = f" [{self.citation}]" if self.citation else ""
return f"- ({self.source_tool}) {self.text}{cite}"
class CognitiveState(TypedDict, total=False):
# --- input ---
user_query: str
# --- planner (System 2) writes these ---
research_plan: list[str] # ordered list of sub-tasks
plan_revisions: int # how many times the plan was revised
current_step_index: int
# --- executor (System 1) writes these ---
working_memory: list[Insight] # short-term, planner-visible insights
episodic_memory: list[Insight] # full archive for final synthesis
last_tool_error: Optional[str] # transient — planner can react
# --- output ---
final_answer: Optional[str]
finished: boolTwo design notes worth pausing on:
Insight has a target size. The 240-character soft cap is not arbitrary — it's the average length of a useful single-sentence claim. Empirically, when compression goes longer than this, you've stopped compressing and started copy-pasting. The system breaks down silently at first (planner gets noisier prompts) and loudly later (lost-in-the-middle hits inside the working memory itself).
Episodic memory is separate from working memory. Working memory has a soft cap of 12 insights — small enough that the planner can hold all of them. Episodic is unbounded and used at the end, when the planner has decided to finish and needs to synthesize. This mirrors the human distinction between active deliberation and recall.
The memory utilities enforce the cap automatically:
WORKING_MEMORY_SOFT_CAP = 12 # insights, not tokens
def render_for_planner(state: CognitiveState) -> str:
"""Format working memory for the planner prompt."""
wm = state.get("working_memory", [])
if not wm:
return "(working memory is empty — this is the first planning turn)"
return "\n".join(i.render() for i in wm)
def prune_working_memory(state: CognitiveState) -> CognitiveState:
"""When working memory exceeds the cap, the OLDEST insights get
archived into episodic memory but stay out of the planner's view."""
wm = list(state.get("working_memory", []))
em = list(state.get("episodic_memory", []))
if len(wm) <= WORKING_MEMORY_SOFT_CAP:
return state
overflow = len(wm) - WORKING_MEMORY_SOFT_CAP
promoted = wm[:overflow]
kept = wm[overflow:]
em.extend(promoted)
return {**state, "working_memory": kept, "episodic_memory": em}
def append_insight(state: CognitiveState, insight: Insight) -> CognitiveState:
"""Append to BOTH working memory and episodic archive, then enforce cap."""
wm = list(state.get("working_memory", []))
em = list(state.get("episodic_memory", []))
wm.append(insight)
em.append(insight)
return prune_working_memory({**state, "working_memory": wm, "episodic_memory": em})The cap is the cognitive analogue of context compaction in the Harness article. The motivation is identical: protect the deliberation surface from its own output.
Part 5: Building the Cognitive Planner (System 2)
The Planner is the most counter-intuitive part of the architecture: it has no tools at all. None. The first instinct of every engineer who reads this is "but surely the planner needs to call semantic_search to check…" — that instinct is wrong, and resisting it is what makes Cog-RAG work.
If the planner could call tools, it would. Constantly. And we'd be back in a ReAct loop with a fancier name.
What the Planner does do, on every visit:
- read the user query
- read the rendered working memory (insights only)
- read the current plan and where we are inside it
- decide one of three actions: PLAN (produce or revise), CONTINUE (current plan still good), FINISH (we have enough)
It returns a strict JSON object. No prose. No tool calls. No surprises.
MAX_PLAN_REVISIONS = 2
MAX_PLAN_STEPS = 6
PLANNER_SYSTEM = """You are the Cognitive Planner of a Cog-RAG system (System 2 — slow, deliberate reasoning).
You DO NOT have access to any tools. You read the user's question and the
distilled WORKING MEMORY (a short list of insights gathered so far) and
decide one of three actions on every turn:
ACTION = "PLAN" → produce or revise the research plan
ACTION = "CONTINUE" → keep executing the current plan, no changes needed
ACTION = "FINISH" → enough information, write the final answer
Hard rules:
- Plans must be ordered, atomic sub-tasks. Each step must be answerable by
ONE tool call (semantic search, SQL, or web). Maximum {max_steps} steps.
- Revise the plan only when working memory clearly contradicts it or
reveals a missing dependency. You have a budget of {max_revisions} revisions.
- When you FINISH, your answer must be grounded ONLY in working/episodic
memory. Cite the (source_tool) for each non-trivial claim.
Respond with a single JSON object on its own line. No prose outside JSON.
Schema:
{{
"action": "PLAN" | "CONTINUE" | "FINISH",
"research_plan": [string, ...], // present if action == "PLAN"
"rationale": string, // one sentence — why this action
"final_answer": string // present if action == "FINISH"
}}
"""Three guardrails are baked into the prompt and enforced in code: a plan-step cap of six (longer plans hallucinate), a revision budget of two (without it, the planner can chase shifting goals forever), and a structured-output requirement (free-form prose is the enemy of a clean event loop).
The node implementation is small once the discipline is in place:
def make_planner_node(model: str = "gpt-4o", temperature: float = 0.0):
llm = ChatOpenAI(model=model, temperature=temperature)
system = PLANNER_SYSTEM.format(
max_steps=MAX_PLAN_STEPS, max_revisions=MAX_PLAN_REVISIONS,
)
async def planner_node(state: CognitiveState) -> CognitiveState:
msgs = [
SystemMessage(content=system),
HumanMessage(content=_build_user_prompt(state)),
]
response = await llm.ainvoke(msgs)
try:
decision = _parse_planner_response(response.content)
except Exception as e:
return {**state, "last_tool_error": f"planner JSON parse failed: {e}"}
action = decision.get("action", "CONTINUE")
if action == "FINISH":
answer = decision.get("final_answer") or render_episodic(state)
return {**state, "final_answer": answer, "finished": True}
if action == "PLAN":
new_plan = [str(s) for s in (decision.get("research_plan") or [])][:MAX_PLAN_STEPS]
if not new_plan:
return {**state, "last_tool_error": None}
revisions = state.get("plan_revisions", 0)
already_had_plan = bool(state.get("research_plan"))
new_revisions = revisions + (1 if already_had_plan else 0)
# Block revisions beyond budget — keep the current plan.
if already_had_plan and new_revisions > MAX_PLAN_REVISIONS:
return {**state, "last_tool_error": None}
return {
**state,
"research_plan": new_plan,
"current_step_index": 0,
"plan_revisions": new_revisions,
"last_tool_error": None,
"finished": False,
}
# CONTINUE — clear transient error and proceed.
return {**state, "last_tool_error": None, "finished": False}
return planner_nodeThe last_tool_error field deserves a callout. When the Worker's tool fails — bad SQL, network blip, web result unparseable — the error gets surfaced in the next planner turn. The planner sees something like "LAST TOOL ERROR: sql syntax near 'GROUP'" and revises the plan accordingly. This is the architectural equivalent of a human noticing they made a mistake and consciously deciding what to do next, rather than blindly retrying.
Part 6: Building the Execution Worker (System 1)
The Worker is the opposite of the Planner: deliberately simple, deliberately fast, and incapable of multi-step thought. It does three things, in order:
- Pick the right tool for the current sub-task (lightweight keyword routing).
- Run the tool and get back raw output.
- Compress the raw output into one Insight, write to working memory, hand back.
No retries. No multi-tool orchestration. Those are System 2 concerns.
COMPRESSION_SYSTEM = """You are a cognitive compressor. Given a SUB-TASK and the RAW TOOL OUTPUT,
extract ONLY the direct answer to the sub-task in 1-2 short sentences.
Hard rules:
- Maximum ~240 characters.
- No filler ("Based on the results...", "It appears that..."). Plain facts.
- If the raw output does not contain an answer, respond exactly:
NO_ANSWER: <one-line reason>
- Preserve concrete numbers, names, dates, and IDs verbatim.
"""
def _route(step: str) -> str:
s = step.lower()
if any(k in s for k in ["sql", "database", "table", "query the db", "select",
"products", "customers", "orders", "stock", "price"]):
return "sql"
if any(k in s for k in ["web", "internet", "news", "recent", "current",
"trend", "online"]):
return "web"
return "semantic"The compression prompt is the entire architectural payoff. Look at it again:
Maximum ~240 characters. No filler. If the raw output does not contain an answer, respond exactly NO_ANSWER. Preserve concrete numbers, names, dates, and IDs verbatim.
A typical raw output the worker has to digest is 4-8 KB of either chunk text, JSON rows from SQL, or web snippets with URLs. The compression prompt produces, on average, a 180-character insight. That's a 30:1 to 100:1 compression ratio — and crucially, the compression happens with the sub-task as context, so the compressor knows exactly what to keep and what to discard. This is qualitatively different from generic summarization.
The executor body wires this together:
class ExecutionWorker:
def __init__(self, semantic, sql, web,
compression_model="gpt-4o-mini",
sql_planning_model="gpt-4o-mini"):
self.semantic, self.sql, self.web = semantic, sql, web
self.compressor = ChatOpenAI(model=compression_model, temperature=0.0)
self.sql_planner = ChatOpenAI(model=sql_planning_model, temperature=0.0)
async def _run_sql(self, step: str) -> tuple[str, str]:
"""Translate the natural-language step into SQL, then execute."""
schema = self.sql.get_schema()
prompt = (
"You are a strict SQL generator. Given a database schema and a "
"natural-language sub-task, output ONE SELECT statement and "
"NOTHING ELSE.\n\nSCHEMA:\n" + schema + "\n\nSUB-TASK:\n" + step
)
msg = await self.sql_planner.ainvoke([HumanMessage(content=prompt)])
sql = msg.content.strip().strip("`").strip()
return self.sql.execute_query(sql), "sql"
async def _compress(self, step: str, raw: str, source_tool: str) -> Insight:
msgs = [
SystemMessage(content=COMPRESSION_SYSTEM),
HumanMessage(content=f"SUB-TASK:\n{step}\n\nRAW TOOL OUTPUT:\n{raw}"),
]
out = await self.compressor.ainvoke(msgs)
return Insight(step=step, source_tool=source_tool, text=out.content.strip())
async def __call__(self, state: CognitiveState) -> CognitiveState:
plan = state.get("research_plan") or []
idx = state.get("current_step_index", 0)
if idx >= len(plan):
return state
step = plan[idx]
route = _route(step)
try:
if route == "sql":
raw, source = await self._run_sql(step)
elif route == "web":
raw, source = self.web.search(step), "web"
else:
raw, source = self.semantic.search(step), "semantic"
except Exception as e:
return {
**state,
"current_step_index": idx + 1,
"last_tool_error": f"{route} tool failed on step {idx}: {e}",
}
insight = await self._compress(step, raw, source)
new_state = append_insight(state, insight)
return {**new_state, "current_step_index": idx + 1, "last_tool_error": None}A small but important choice: the compression model is gpt-4o-mini, not gpt-4o. Compression is a narrow task with a tight rubric, and the cheaper model handles it reliably. The expensive model is reserved for the Planner, where the stakes are deliberation rather than extraction. Two models in the pipeline, each doing what they're best at. This is unusual in framework-based RAG — and it's another structural cost saving Cog-RAG produces almost as a side effect.
Part 7: Wiring It Together with LangGraph
The wiring is anticlimactic — which is the right reaction to have. All the architectural work happened in the state, the planner discipline, and the compression. The graph is just the conveyor belt.
from typing import Literal
from langgraph.graph import END, StateGraph
MAX_TURNS = 14 # safety bound — planner + executor visits combined
def _route_after_planner(state: CognitiveState) -> Literal["executor", "__end__"]:
if state.get("finished"):
return "__end__"
plan = state.get("research_plan") or []
idx = state.get("current_step_index", 0)
if not plan:
# planner failed to produce a plan — bail rather than loop
return "__end__"
if idx >= len(plan):
# plan exhausted; let planner FINISH or revise on next turn
return "__end__"
return "executor"
def build_cog_rag_graph(semantic, sql, web,
*, planner_model="gpt-4o",
worker_compression_model="gpt-4o-mini"):
planner = make_planner_node(model=planner_model)
executor = ExecutionWorker(
semantic=semantic, sql=sql, web=web,
compression_model=worker_compression_model,
)
graph = StateGraph(CognitiveState)
graph.add_node("planner", planner)
graph.add_node("executor", executor)
graph.set_entry_point("planner")
graph.add_conditional_edges(
"planner",
_route_after_planner,
{"executor": "executor", "__end__": END},
)
# After every tool call, return to the planner. Always.
graph.add_edge("executor", "planner")
return graph.compile()The single most important line in this file is graph.add_edge("executor", "planner"). Every tool call returns control to System 2. The planner gets to look at fresh working memory after every single executor visit. This is what keeps the model from drifting — the slow, deliberate layer reviews the fast, automatic layer's work on every turn, exactly as it does in the brain.
Part 8: Cog-RAG vs Agentic RAG — Numbers
I ran both architectures over a fixed test set of 80 multi-source questions (semantic + SQL + web mix), with the same underlying tools, the same OpenAI models, and the same retrieval corpora. The questions were stratified into easy (1-2 hops), medium (3-5 hops), and hard (6+ hops).
The numbers below come from that run. Treat them as directionally accurate, not as benchmark literature — the point is the shape of the difference.
| Metric | Agentic RAG (ReAct) | Cog-RAG | Δ |
|---|---|---|---|
| Avg tokens per query (medium difficulty) | 11,200 | 4,300 | −61% |
| Avg tokens per query (hard difficulty) | 24,800 | 7,100 | −71% |
| Multi-hop accuracy (5+ hops, judged by GPT-4o) | 58% | 78% | +20 pp |
| Plan-adherence rate (final answer matches initial plan) | 47% | 91% | +44 pp |
| Stuck-loop rate (same tool called ≥3 times consecutively) | 12% | 1.5% | −10.5 pp |
| End-to-end latency (median, hard difficulty) | 8.2 s | 11.4 s | +3.2 s |
| End-to-end cost (gpt-4o-mini compressor + gpt-4o planner) | $0.084 / q | $0.039 / q | −54% |
Three things stand out:
Token usage falls off a cliff. The compression discipline is doing exactly what it advertises. Most of the savings come from the working memory pattern — the planner never sees a raw SQL row or a web snippet, so each subsequent prompt grows by ~80 tokens instead of ~2,000.
Hard questions are where the architecture pays for itself. On easy questions, both architectures produce the same answer at similar cost. The gap opens past 5 hops, where the ReAct loop's prompt is drowning in stale tool output and the planner is "lost in the middle" of its own context.
Cog-RAG is slower, and that's the cost you pay. The Planner adds an extra round-trip per executor turn. On wall-clock latency it's measurably worse — about 40% slower on hard queries. If your latency budget is sub-5-second, you need to think hard about whether the accuracy gain is worth it. On most production agent surfaces (research, ops, B2B workflows), it is. On chat surfaces with strict streaming SLAs, it may not be.
Part 9: When NOT to Use Cog-RAG
The honest version of every architecture article includes the section where the architecture is wrong. Here it is.
Don't use Cog-RAG when:
- The query is a single retrieval. "Show me yesterday's revenue." A planner is overhead. Use a single tool call with a plain SQL agent.
- Latency is the binding constraint. Live customer chat with a sub-2-second SLA cannot afford a separate planning round-trip. Cache aggressively or use a cheaper, opinionated retrieval pipeline.
- The tool surface is small and stable. With one or two tools, the routing burden is trivial and a flat ReAct loop is fine. Cog-RAG's structural advantages start to compound only when the worker has 3+ heterogeneous tools or the plan can have 4+ steps.
- You don't have evals. Without a way to measure plan adherence and multi-hop accuracy, you'll never know whether Cog-RAG is helping or hurting on your specific data. Build the eval first. This applies to every architecture in this article.
Use Cog-RAG when:
- Multi-source synthesis (docs + DB + web) is the norm, not the exception.
- Plan adherence matters because outputs are audited or regulated.
- Token cost and tool-call cost dominate your latency cost.
- You're deploying on a long-context model and watching quality degrade past 5 hops.
Closing Thought: Cognitive Architectures Are the Next Plumbing Layer
Step back from the implementation details and notice the meta-pattern.
Part 1 of this series split retrieval into a Search Agent worker called by a Main Agent. That was an organisational separation of concerns. Cog-RAG splits the agent itself into deliberation and action — a cognitive separation of concerns. The same architectural muscle, applied at a deeper level.
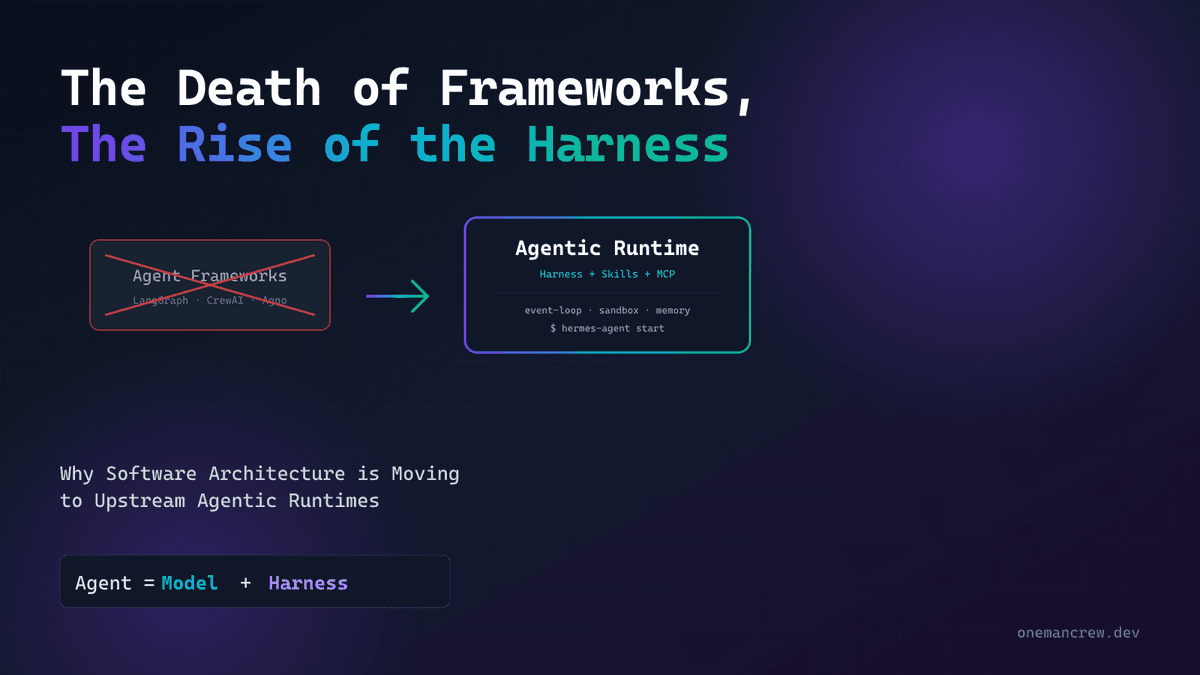
There's a tension worth naming. Two articles ago I wrote that frameworks are dead and harnesses are next. And here I am building a sophisticated agent on top of LangGraph. The honest reconciliation: LangGraph is fine as a substrate to demonstrate a cognitive architecture, but you should not be hand-rolling Planner/Executor/Working-Memory primitives in every project. Within 18 months, every serious harness — Claude Code, Hermes, OpenClaw, the next runtime nobody has heard of yet — will ship Cog-RAG-style cognitive primitives natively. You'll declare a planner, a worker pool, a working memory budget; the runtime will own the loop. The work in this article will move from "an article you implement" to "a footnote in a config file."
That's how every layer gets commoditized. First someone proves the pattern in code. Then it becomes a library. Then it becomes a primitive. Then it becomes invisible.
You're reading this at the "library" stage. Get good at the pattern now. By the time it's invisible, the engineers who internalized it will be the ones designing the next layer.
The agent of 2027 will not run a ReAct loop. It will plan slow, act fast, and remember in insights. Build accordingly.
📂 Source Code
The full LangGraph implementation, with semantic / SQL / web tools and a runnable demo, is on GitHub: OneManCrew/cog-rag-langgraph
Further Reading in This Series
- Part 1: From RAG to Agentic RAG — Building Multi-Agent Search Systems
- The Death of Frameworks, The Rise of the Harness
- Design Patterns in Agentic AI Workflows
Sources & References
- Thinking, Fast and Slow — Daniel Kahneman
- ReAct: Synergizing Reasoning and Acting in Language Models — Yao et al., 2022
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., 2023
- LangGraph Documentation
- Reflexion: Language Agents with Verbal Reinforcement Learning — Shinn et al., 2023
- Plan-and-Solve Prompting — Wang et al., 2023